在敲代码时,弹出广告,广告大概这个样子

咦,小姐姐,cosplay,点进去看看。
好多漂亮的妹子,页面打开很流畅,产品体验极佳。
不过每组图片只能看,如果想打包下载得花rmb。
ctrlC+ctrlV几张后不乐意了,这么保存一来看不到全部图片,二来,麻烦,太麻烦了。
试试吧,看能不能发现点有趣的东东。首先习惯性的看看html源码。

可以看到图片地址几乎都已经出来了,缩略图在前,原图在后,嗯,有点意思,开始扒。
用JAVA写爬虫,配合之前学的ConnectionUtil工具,敲了一晚上,总算把数据爬出来了,
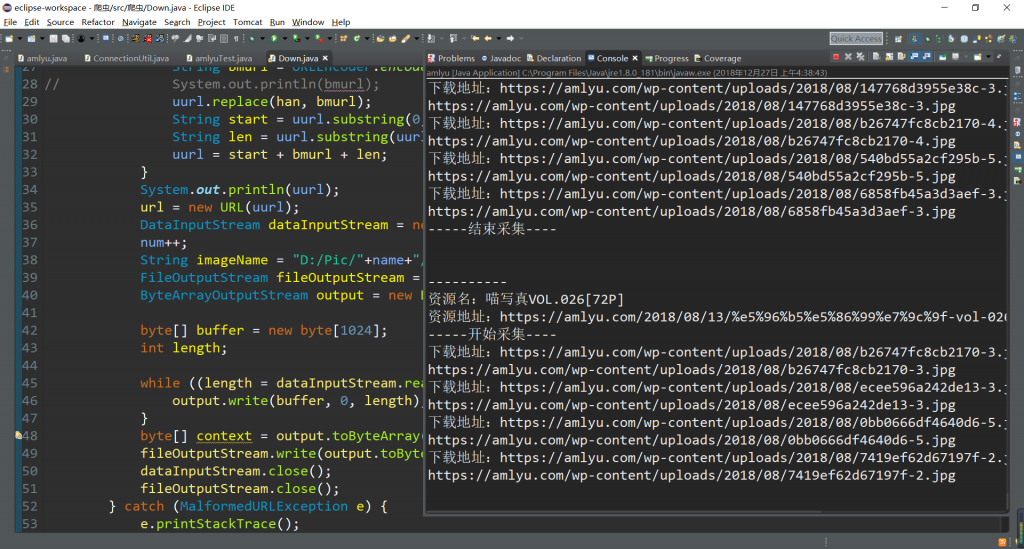
不得不说 ,JAVA的url编码真的恶心,会将整个url链接都进行编码,我也是搞了好大功夫才将中文编码问题解决。
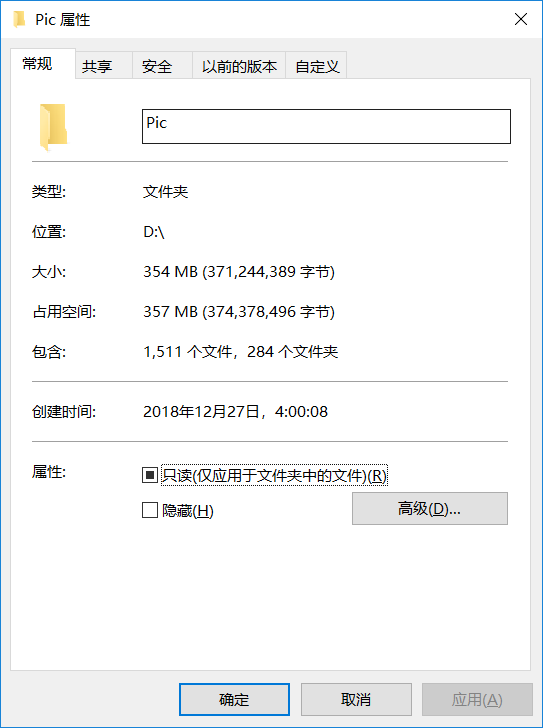
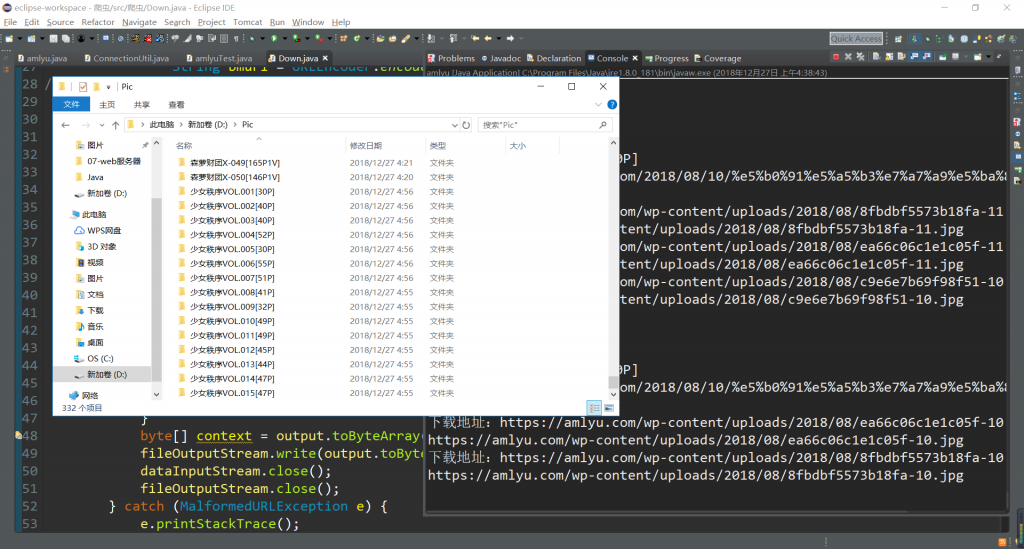
图片还在扒,扒完之后分享。
2018-12-27 更新代码
HomePage类 扒的是图片网址每一个主题图片的网址
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @version 1.0
* @author 苦逼的年轮
*
*/
public class HomePage {
public static void main(String[] args) {
int Picnum;// 这个是网页的页面数
for (Picnum = 1; Picnum < 2; Picnum++) {
String url = "https://amlyu.com/page/" + Picnum;
String result = ConnectionUtil.Connect(url);
result = result.replaceAll(" ", "");// 将页面中的空格去除,方便使用正则表达式
Matcher m = Pattern
.compile("<atarget=\"_blank\"href=\"https://amlyu.com/[\\s\\S]{1,100}/\">[\\s\\S]{1,70}</a>")
.matcher(result);// 通过正则表达式匹配图片的网址
int i = 0;
while (m.find())
i++;// 通过i得出有多少个页面 方便设计数组
String[] stu = new String[i];// 设计图片网址数组
Matcher m2 = Pattern
.compile("<atarget=\"_blank\"href=\"https://amlyu.com/[\\s\\S]{1,100}/\">[\\s\\S]{1,70}</a>")
.matcher(result);// 通过正则表达式匹配图片的网址
int num = 0;
while (m2.find()) {
stu[num++] = m2.group();// 将网址数据存入数组
}
for (int j = 0; j < stu.length; j++) {
int Nbegin = stu[j].indexOf("\">");
int Nfid = stu[j].indexOf("</a>");
String name = stu[j].substring(Nbegin + 2, Nfid);// 采集图片网址名称
System.out.println("资源名:" + name);
int Xbegin = stu[j].indexOf("https://amlyu.com/");
int Xfid = stu[j].indexOf("\">");
String ImgUrl = stu[j].substring(Xbegin, Xfid);// 采集图片网址地址
System.out.println(("资源地址:" + ImgUrl));
System.out.println("-----开始采集----");
// 传入图片网址名称(交给SubPage创建文件夹) 和图片网址(进行下载)
SubPage.Start(name, ImgUrl);
System.out.println("-----结束采集----");
System.out.println();
}
}
}
}
SubPage类 扒当前图片页面所有的图片网址
import java.io.File;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @version 1.0
* @author 苦逼的年轮
*
*/
public class SubPage {
public static void Start(String name, String ImgUrl) {
File file = new File("D:/Pic/");// 创建一个文件夹用于存储文件
if (!file.exists()) {// 如果文件夹不存在
file.mkdir();// 再创建文件夹
}
file = new File("D:/Pic/" + name + "/");// 通过采集到的网址名称创建图片文件夹
if (!file.exists()) {// 如果文件夹不存在
file.mkdir();// 再创建文件夹
}
String result = ConnectionUtil.Connect(ImgUrl);
result = result.replaceAll(" ", "");// 将页面中的空格去除,方便使用正则表达式
Matcher m = Pattern.compile("src=\\\"https://amlyu.com/[\\s\\S]{1,100}\"alt=\"[\\s\\S]{1,100}\"title")
.matcher(result);// 采集图片网址
int i = 0;
while (m.find()) {
i++;// 通过i得出有多少张图片 方便设计数组
}
String[] stu = new String[i];
Matcher m2 = Pattern.compile("src=\\\"https://amlyu.com/[\\s\\S]{1,100}\"alt=\"[\\s\\S]{1,100}\"title")
.matcher(result);
int ImgNum = 0;
while (m2.find()) {
stu[ImgNum++] = m2.group();// 将图片网址录入数组
}
for (int ImgDownNum = 0; ImgDownNum < stu.length; ImgDownNum++) {
int Xbegin = stu[ImgDownNum].indexOf("src=\"");
int Xfid = stu[ImgDownNum].indexOf("\"alt=");
String DownUrl = stu[ImgDownNum].substring(Xbegin + 5, Xfid);// 采集图片下载地址
System.out.println("第" + (ImgDownNum + 1) + "张图片 下载地址:" + DownUrl);
// 传入图片网址名称(告诉DownImg图片属于哪个目录) 图片下载地址 图片的张数
DownImg.Img(name, DownUrl, ImgDownNum);
}
}
}
DownImg类 将图片分类下载到D盘的Pic文件夹下
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @version 1.0
* @author 苦逼的年轮
*
*/
public class DownImg {
public static void Img(String name, String DownUrl, int ImgDownNum) {
try {
String reg = "[\u4e00-\u9fa5]+";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(DownUrl);
while (matcher.find()) {// 重复把汉字进行编码替换
String han = matcher.group(0);// 正则匹配url中的汉字
String bmurl = URLEncoder.encode(han, "UTF-8");// 将汉字进行编码
String start = DownUrl.substring(0, DownUrl.indexOf(han));// 取出出现汉字的前部分
String len = DownUrl.substring(DownUrl.indexOf(han) + han.length(), DownUrl.length());// 取出出现汉字的后部分
DownUrl = start + bmurl + len;// 将汉字编码和前后连接形成新的连接
}
System.out.println("第" + (ImgDownNum + 1) + "张图片下载成功");
URL url = new URL(DownUrl);
// 这里用到 openStream 相比openConnection 后者会得到 modification date 和 http header
// 等东西,而此刻我们不需要
DataInputStream dataInputStream = new DataInputStream(url.openStream());// 创建数据输入流
String imageName = "D:/Pic/" + name + "/" + (ImgDownNum + 1) + ".jpg";// 图片路径
FileOutputStream fileOutputStream = new FileOutputStream(new File(imageName));// 输出流
ByteArrayOutputStream output = new ByteArrayOutputStream();// 字符缓冲区
byte[] buffer = new byte[1024];
int length;// 读取字符的长度
while ((length = dataInputStream.read(buffer)) > 0) {
output.write(buffer, 0, length);
}
fileOutputStream.write(output.toByteArray());// 输出图片
dataInputStream.close();
fileOutputStream.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
将代码进行了美化,现在扒下的结果显示:
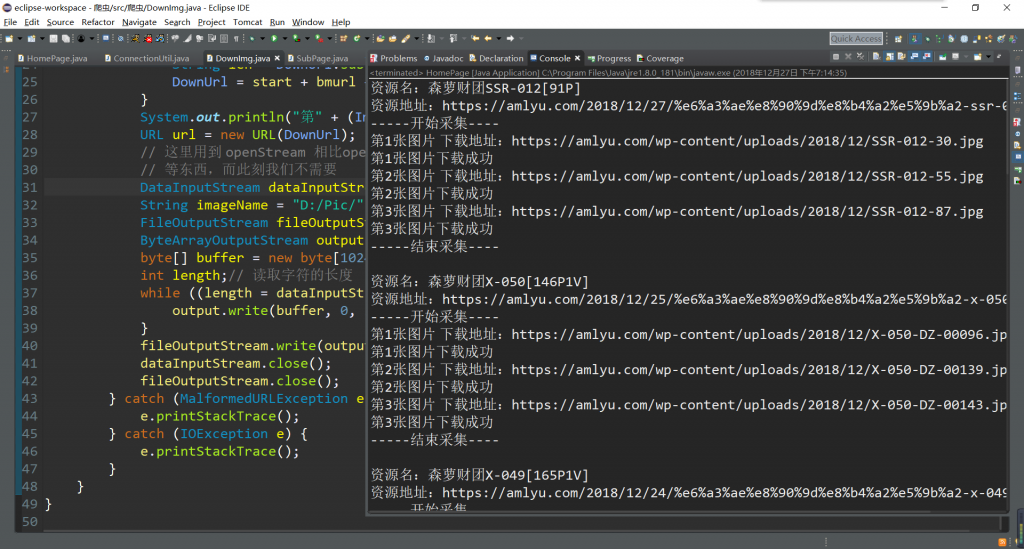
期待已久的来了 图片打包下载地址:
链接: https://pan.baidu.com/s/1qJD1Bb__bQl6lP3U3S0T-Q 提取码:4g4n